在今天的Pandas学习笔记中,我们深入探讨了数据处理的关键环节,重点包括数据重塑和轴向旋转、数据分组及运算、离散化处理以及数据集合并。这些功能为高效处理和分析数据提供了强大支持。
一、数据重塑和轴向旋转
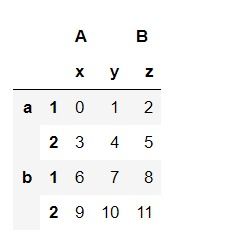
Pandas提供了灵活的数据重塑工具。stack()函数可将列索引转换为行索引,实现数据的堆叠;而unstack()则执行相反操作,将行索引转换为列索引。pivot()和melt()函数分别用于数据透视和逆透视,以适应不同的分析需求。轴向旋转功能通过swaplevel()和reorder_levels()方法调整多层索引的顺序,提升数据操作的灵活性。
二、数据分组和分组运算
使用groupby()方法可以根据指定键对数据进行分组,例如按类别或时间周期。分组后,可应用聚合函数(如sum()、mean()、count())进行统计分析,或使用transform()和apply()方法执行自定义运算。分组运算支持多级分组和条件筛选,便于从多维度洞察数据特征。
三、离散化处理
离散化将连续数据划分为区间,常用于数据分箱或分类。cut()函数根据指定边界将数值数据分段,而qcut()则基于分位数进行等频分割。离散化后,数据可转换为分类变量,便于进行分组统计或可视化,同时减少噪声影响。
四、合并数据集
Pandas支持多种数据合并方式:concat()用于沿轴拼接多个DataFrame;merge()基于键值连接数据集,类似SQL的JOIN操作;join()则按索引合并。这些方法允许处理不同来源的数据,确保数据整合的准确性和效率。
通过掌握这些Pandas核心功能,我们可以更高效地清洗、转换和分析数据,为后续建模和决策打下坚实基础。实践中需注意数据一致性和性能优化,以应对复杂业务场景。