在金融行业中,机器学习与数据科学的融合正以前所未有的速度推动着业务创新。这一切的基础都建立在高质量的数据之上。本系列第五篇将聚焦数据治理中的核心环节——数据处理,探讨其在金融领域的关键作用。
一、数据处理的定义与重要性
数据处理是数据治理的生命线,指的是对原始金融数据进行收集、清洗、转换和整合的过程。在金融行业,由于数据来源多样(如交易记录、客户信息、市场数据等),且往往存在噪音、缺失值或格式不一致的问题,高质量的数据处理成为确保模型准确性的前提。
二、数据处理的核心步骤
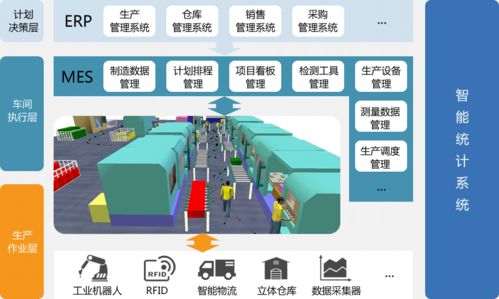
- 数据收集与提取:金融数据通常分布在多个系统(如核心银行系统、风控平台、外部数据接口)中。数据处理的第一步是整合这些异构数据源,确保全面覆盖业务需求。
- 数据清洗与验证:金融数据对准确性要求极高。清洗过程包括处理异常值(如突发的交易峰值)、填补缺失值(例如使用历史均值或机器学习插补法),以及验证数据一致性(如检查账户余额与交易记录的匹配)。
- 数据转换与标准化:将原始数据转化为模型可用的格式。例如,将非结构化文本(如客户反馈)通过自然语言处理技术转换为数值特征,或对时间序列数据进行归一化以消除量纲影响。
- 数据集成与存储:处理后的数据需整合成统一视图,并存储在安全、可访问的环境中(如数据湖或数据仓库),为后续分析和建模提供支持。
三、金融行业的特殊挑战与对策
金融数据处理面临诸多独特挑战:
- 合规性要求:如GDPR、巴塞尔协议等法规对数据隐私和存储有严格规定,需在处理过程中嵌入脱敏和加密机制。
- 实时性需求:高频交易或风险监控场景需要流式数据处理技术(如Apache Kafka)的支持。
- 数据质量追溯:金融审计要求数据处理全流程可追溯,需建立元数据管理和血缘跟踪系统。
四、数据处理与机器学习的协同
在机器学习项目中,数据处理通常占据70%以上的工作量。有效的处理不仅能提升模型性能(如通过特征工程生成更有预测力的变量),还能减少过拟合风险。例如,在信用评分模型中,通过处理历史还款数据生成“逾期频率”等衍生特征,可显著增强模型的判别能力。
数据处理是数据治理的基石,尤其在高度依赖数据的金融行业,其质量直接决定了机器学习应用的成败。在下篇中,我们将深入探讨数据治理的另一个关键环节——数据安全管理,敬请关注。