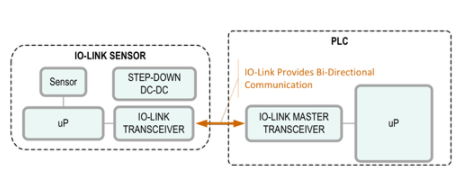
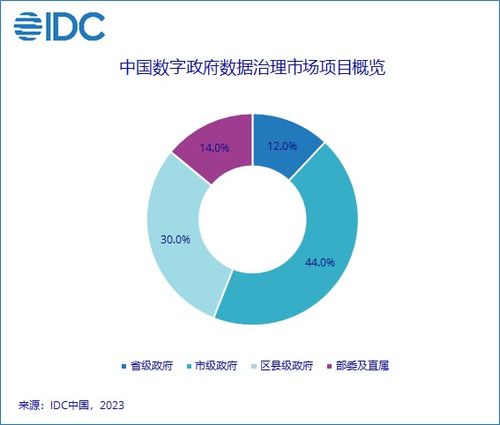
Python已成为数据处理领域的首选语言,其丰富的库和简洁的语法使数据清洗、分析和可视化变得轻而易举。本文分享一份免费的Python数据处理代码合集,涵盖常见场景的解决方案,帮助初学者和专业人士快速上手。
一、数据读取与预处理
使用pandas库可以轻松读取多种格式的数据。例如,从CSV文件读取数据:`python
import pandas as pd
data = pd.readcsv('data.csv')`
数据清洗时,常用代码处理缺失值:`python
data.fillna(0, inplace=True) # 用0填充缺失值
data.dropduplicates(inplace=True) # 删除重复行`
二、数据转换与计算
利用numpy和pandas进行数值计算和列操作:`python
import numpy as np
data['newcolumn'] = data['oldcolumn'] * 2 # 创建新列
data['log_value'] = np.log(data['value']) # 应用对数变换`
分组统计示例:`python
grouped = data.groupby('category')['sales'].sum() # 按类别汇总销售额`
三、数据可视化
matplotlib和seaborn库能快速生成图表:`python
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10,6))
sns.histplot(data['age'], kde=True)
plt.title('年龄分布图')
plt.show()`
四、高级处理技巧
对于时间序列数据,可使用pandas的resample方法:`python
data['date'] = pd.todatetime(data['date'])
monthlydata = data.set_index('date').resample('M').mean() # 按月重采样`
免费代码合集下载说明:
本合集包含完整示例文件,涵盖数据合并、过滤、异常值处理等场景。访问GitHub仓库(示例链接:github.com/dataprocessing/python-tools)可直接下载,所有代码均开源且附带注释,适合学习和直接应用。
通过掌握这些核心代码,您能显著提升数据处理效率。建议结合实际项目练习,逐步探索更复杂的库如Scikit-learn用于机器学习,或Dask处理大规模数据。