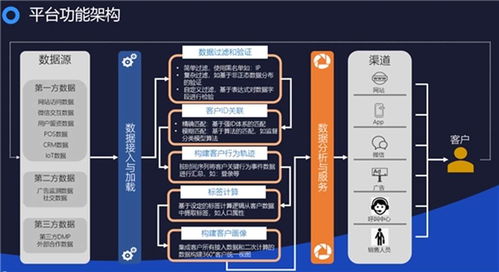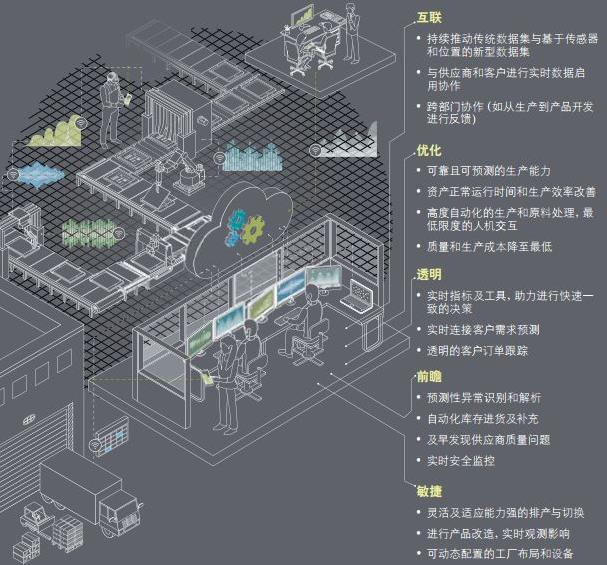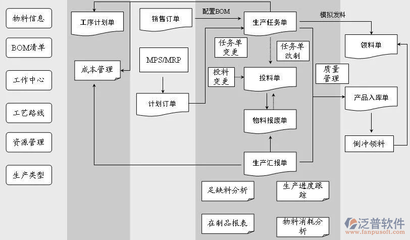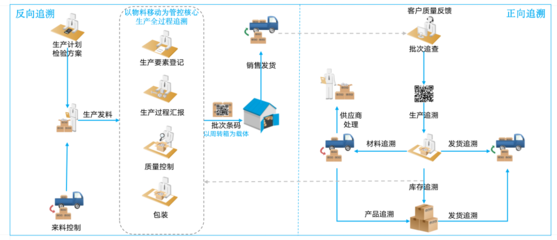
在数据驱动的时代,高效、可靠地处理海量数据已成为企业和研究机构的核心竞争力。大数据处理工具作为这一过程中的关键基础设施,已发展出多样化的技术栈,以满足不同场景下的计算需求。本文将系统梳理当前主流的大数据处理工具,并探讨其技术特点与应用场景。
一、批处理引擎:处理历史数据的基石
批处理主要针对静态、大规模的历史数据集进行计算,其典型代表是Apache Hadoop生态圈。
- Apache Hadoop:作为开源分布式计算框架的鼻祖,Hadoop的核心组件包括分布式文件系统HDFS和计算框架MapReduce。它通过将数据分片存储在多台机器上,并利用MapReduce编程模型进行并行处理,实现了对PB级数据的可靠、可扩展处理。尽管MapReduce的编程模型相对复杂,但其高容错性和成熟生态使其在离线数据分析、日志处理等领域仍占有一席之地。
- Apache Spark:作为Hadoop MapReduce的革新者,Spark凭借其内存计算和弹性分布式数据集(RDD)模型,将批处理性能提升了数十倍。Spark提供了丰富的API(支持Scala、Java、Python和R),并集成了SQL查询(Spark SQL)、机器学习(MLlib)、图计算(GraphX)和流处理(Spark Streaming)等模块,形成了一个统一的数据处理平台。其卓越的性能和易用性使其成为当前最受欢迎的批处理框架之一。
二、流处理引擎:实时数据洞察的利器
随着物联网和实时业务监控的普及,对数据流进行低延迟处理的需求日益增长。
- Apache Kafka:严格来说,Kafka是一个分布式消息队列,但它已成为流处理生态的事实标准数据总线。Kafka的高吞吐、持久化和分布式特性,使其能够可靠地处理实时数据流,并为下游处理系统提供数据源。
- Apache Flink:作为一个真正的流处理优先框架,Flink将批处理视为流处理的特例。它提供了精确一次(exactly-once)的状态一致性保证、低延迟和高吞吐的流处理能力,以及复杂事件处理(CEP)和机器学习库。Flink在实时欺诈检测、监控告警等场景中表现出色。
- Apache Storm:作为早期的流处理框架,Storm提供了简单的编程模型和可靠的实时计算能力,虽然其吞吐量不及Flink,但在一些对延迟极其敏感的场景中仍有应用。
三、查询与分析引擎:交互式数据探索
为了便于数据分析师和业务人员直接查询大数据,一系列SQL-on-Hadoop和交互式查询引擎应运而生。
- Apache Hive:基于Hadoop的数据仓库工具,通过将SQL语句转换为MapReduce任务(后续也支持Spark、Tez等引擎)来查询大数据。其表结构和元数据管理功能,使其在企业数据仓库建设中广泛应用。
- Presto / Trino:由Facebook开发的分布式SQL查询引擎,能够查询多种数据源(如HDFS、MySQL、Kafka等)中的数据,且无需将数据迁移到统一存储。其低延迟的交互式查询能力,特别适用于即席查询和数据分析。
- Apache Druid:专为实时 OLAP 查询设计的列式存储,能够对流入的数据进行亚秒级查询。它在实时监控、点击流分析等场景中具有显著优势。
四、云原生与全托管服务
随着云计算的发展,各大云厂商提供了全托管的大数据服务,降低了运维复杂度。
- Amazon EMR、Google Dataproc、Azure HDInsight:这些云托管服务提供了集成的Hadoop和Spark集群,用户可以快速部署和伸缩,并与其他云服务(如存储、数据库)无缝集成。
- Snowflake、BigQuery、Redshift:这些云数据仓库提供了完全托管的、高性能的SQL查询服务,将计算与存储分离,实现了极高的弹性与并发能力。
五、工具选型考量
面对如此丰富的工具集,选择合适的技术栈需综合考虑以下因素:
- 数据特性:数据规模、增长速度、是静态还是连续流。
- 处理模式:是否需要实时结果,还是允许分钟级甚至小时级的延迟。
- 团队技能:团队对编程语言(Java/Scala/Python)和框架的熟悉程度。
- 生态系统:工具与现有数据源、存储系统及其他组件的集成能力。
- 运维成本:自建集群的运维复杂度与云托管服务的费用权衡。
###
大数据处理工具生态已从Hadoop一枝独秀发展为百花齐放的局面。没有一种工具能够解决所有问题,现代数据架构往往采用混合模式,例如使用Kafka作为数据管道,Flink进行实时处理,Spark进行复杂批处理与分析,并将结果存储于数据仓库(如Hive或Snowflake)以供查询。理解各类工具的核心优势与适用边界,是构建高效、健壮数据平台的关键。随着计算存储分离、湖仓一体和实时化趋势的深入,大数据处理工具将继续向着更易用、更融合、更智能的方向演进。