在当今这个信息爆炸的时代,大数据已经渗透到我们生活的方方面面,从商业决策、医疗健康到城市规划、科学研究,无处不在。海量的原始数据本身价值有限,只有经过精心的“加工”——即数据处理——才能转化为真正有用的信息、知识和洞见。本文将带您走进数据处理的世界,一探其究竟。
一、什么是数据处理?
数据处理是指对收集到的原始数据进行一系列操作,包括清洗、转换、整合、分析和可视化等,其目标是将其转化为结构化的、易于理解和使用的格式,以支持决策、发现规律或驱动智能应用。它是连接原始数据与最终价值的桥梁,是整个大数据价值链中最核心的环节之一。
二、数据处理的关键步骤
一个完整的数据处理流程通常包含以下几个核心阶段:
- 数据采集与集成:从各种来源(如传感器、日志文件、数据库、社交媒体)收集原始数据,并将其汇集到一起。
- 数据清洗与预处理:这是至关重要的一步,旨在处理“脏数据”,如纠正错误、填补缺失值、消除重复、统一格式、处理异常值等,确保数据的质量和一致性。
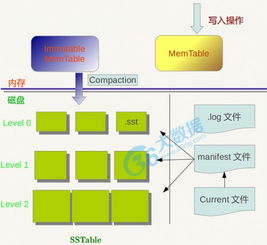
- 数据存储与管理:将清洗后的数据高效、可靠地存储起来,可能涉及分布式文件系统(如HDFS)、NoSQL数据库(如HBase、MongoDB)或数据仓库等技术。
- 数据转换与计算:根据分析目标,对数据进行聚合、过滤、关联、计算衍生指标等操作。这一过程可能涉及批处理(如使用MapReduce、Spark处理历史数据)或流处理(如使用Flink、Storm处理实时数据流)。
- 数据分析与挖掘:运用统计分析、机器学习、深度学习等算法,从数据中发现模式、趋势、关联和预测未来。
- 数据可视化与呈现:将分析结果以图表、仪表盘等直观形式展现出来,使非技术人员也能轻松理解数据背后的故事。
三、核心技术框架与工具
为应对大数据处理的挑战(体量大、速度快、类型多、价值密度低),一系列强大的技术栈应运而生:
- 批处理框架:如Apache Hadoop(MapReduce)和Apache Spark,擅长处理海量的、静态的历史数据集,进行复杂的批量计算。
- 流处理框架:如Apache Flink、Apache Storm和Spark Streaming,能够对连续不断产生的数据流进行实时或近实时的处理和分析。
- 数据处理引擎/查询引擎:如Apache Hive、Presto、Impala,提供了类SQL的接口,方便分析师对大规模数据进行查询和分析。
- 资源管理与协调框架:如Apache YARN和Kubernetes,负责管理和调度集群的计算资源。
四、数据处理的应用价值
高效的数据处理能力是解锁大数据价值的关键。它使得:
- 企业智能决策:通过分析销售、用户行为等数据,优化产品、营销和运营策略。
- 个性化服务:例如,电商平台的推荐系统、新闻资讯的个性化推送,都依赖于对用户数据的实时处理。
- 风险管控与预测:金融领域的欺诈检测、信用评估,工业领域的设备预测性维护,都离不开对海量数据的快速处理与分析。
- 科学研究突破:在天文、生物信息学等领域,处理PB级的数据已成为常态,推动了重大科学发现。
五、未来趋势与挑战
随着数据量的持续增长和技术的不断演进,数据处理领域也在快速发展:
- 实时化与智能化:对数据处理速度的要求越来越高,实时流处理与AI/ML的结合日益紧密。
- 湖仓一体与数据编织:打破数据湖与数据仓库的界限,构建更灵活、统一的数据架构,简化数据管理和处理流程。
- 自动化与低代码/无代码:自动化数据管道构建、数据质量监控,以及面向业务人员的低代码数据分析工具,正降低数据处理的门槛。
- 隐私与安全:在数据处理全过程中,如何保护个人隐私和数据安全,是必须面对的严峻挑战。
数据处理是大数据生态系统的引擎。理解并掌握数据处理的技术与流程,意味着掌握了从数据金矿中提炼真金的能力。它不仅是技术专家的领域,也逐渐成为每一位希望从数据中获益的现代人所应具备的基本素养。